For your first issue...
While it may not seem so at first, this is actually a challenging problem. Unfortunately, AWS Textract (our OCR engine) ignores the extra whitespace between rows AND your rows vary in height (1-3 lines or more), so just counting line breaks isn't going to be enough.
I experimented a little and found that with Quick Fields, which uses OmniPage OCR, the whitespace is preserved better (though it still doesn't preserve extra line breaks) and you may be able to use that extra whitespace to finagle it to work. For this case.
For example:
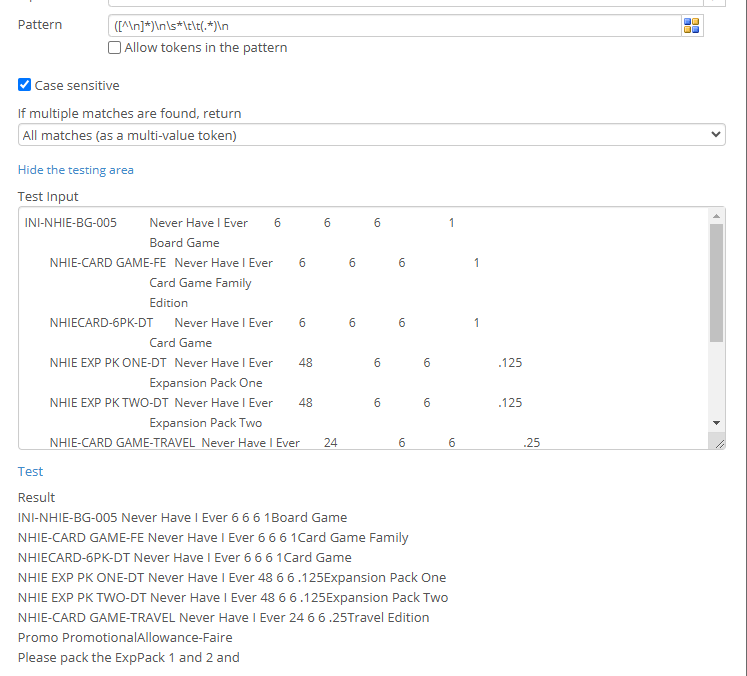
Correctly breaks the rows apart, keeping all parts of the description. Using a second regular expression (or possibly making this one more complex, though I don't recommend it) could allow you to strip the numbers and decimal point that exist between the lines of description (e.g., something like \s([^\d]*\s+)\d+\s+\d+\s+\d+\s+\.?\d+([^\d]+), but this isn't perfect...)
For your second issue... there are two approaches, as you mentioned.
Fixing the OCR quality
When you import the PDF and generate its pages, make sure that a high enough resolution is being used (note that this is different than how its generated in the Capture Profile Designer--don't use that as your basis as there's a bug that causes it to generate too low of a resolution for some PDFs). I experimented with this and found that both AWS Textract and OmniPage could successfully capture the decimal points on the sample you provided.
Calculating the column value
This is pretty trivial to do with a Token Calculator activity, assuming you have each value (the dividend and divisor) as tokens. Getting those values, again, may be harder and require doing something like we discussed in this post with complex regular expressions.
At the end of the day, though, what you're trying to do (in this post and others) is called "line item extraction" and it's just not something we currently natively support (it's also incredibly difficult to make a generalized solution for--third party solutions currently exist but the quality of their results has been pretty low...).