I would classify this as semi-structured data--it's not totally consistent but it does have some structure and pattern to it. That makes it challenging to deal with, but it may be possible to extract. In particular, I think regular expressions (via the Pattern Matching activity in Workflow) are going to be your best strategy here (along with using zones to only extract the data from parts of the image).
However, you need a larger sample size to build robust regular expressions--samples that include most/all of the possible variations.
Example questions:
Is "UPC" always present?
Is it always a number prefixed by the text "UPC:"?
Is there always at least one Batch?
Does it always have a "Batch:" label?
Will there always be a material number?
Will every material number have a description?
Are the column widths always the same?
Given what you've shown in your post, you can do something like the following:
- Create a MV token containing the material numbers (each row corresponds to one value in the token)
- Create a MV token containing the description (each row corresponds to one value in the token--and importantly, the same value as the material number)
- Use additional regular expressions to extract each part of the description for each row. Using a For Each Value activity to iterate over each value in token created by Step 2 would probably be the easiest way to do this.
If this is done correctly, you can then correlate the values in the multi-value tokens by their index (i.e., the first value in each token will correspond to the first row's values, the second value to the second row's values, etc.).
See bottom of this post for more details about the regular expressions that might work.
Regarding:
I know that I can have a single field with multiple values, and I can extract the batch, description, qty, and UPC but I don't think that there's anything like a table field
Laserfiche has something called Multi-Value Field Groups that act sort of like "field-level records" and may be what you're looking for.
One additional challenge you're going to have to deal with is how correlate multiple batches to a single item (e.g., a comma-separated list might work since they are numbers) or, alternatively, to expand the batches into multiple rows that use the same material number (depending on what you want).
Note: The "split" token function can easily split apart comma-separated value lists and token indexing can easily recombine them.
Sample regular expressions that might help you get started, but again, aren't very robust because you only posted a very limited sample size.
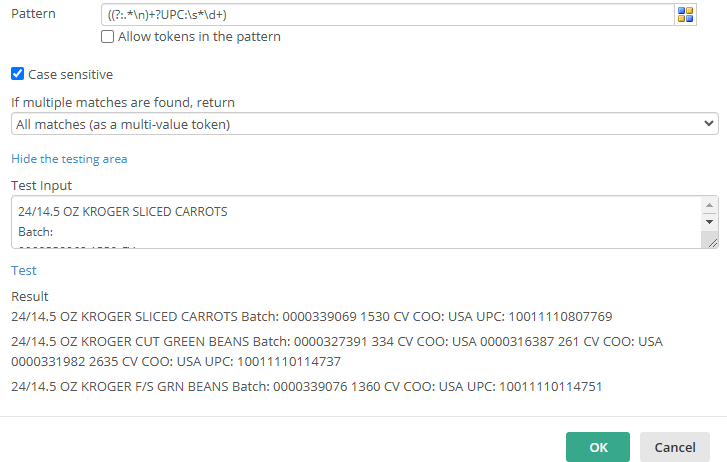
1) To split the Description column into rows (assuming they have a UPC):
((?:.*\n)+?UPC:\s*\d+)
This captures everything before and including "UPC: <number>" (including line breaks).
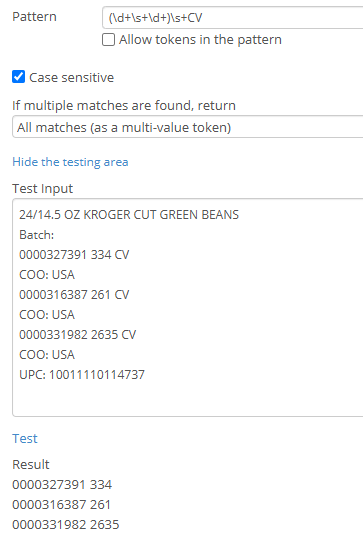
2) To extract the batch numbers from a Description row (assuming they always end with CV):
(\d+\s+\d+)\s+CV
This captures the digits (and whitespace between the digits) before the letters CV.
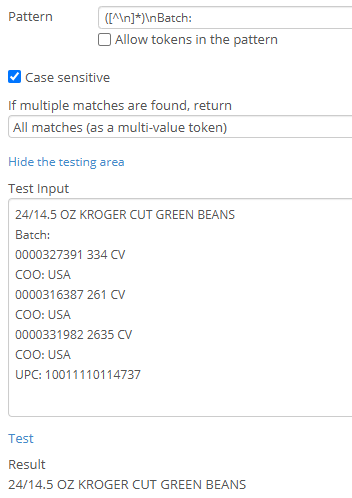
3) To get the item name from the Description row (assuming they always have a batch number):
([^\n]*)\nBatch:
This captures all non-line break characters before the word "Batch:"
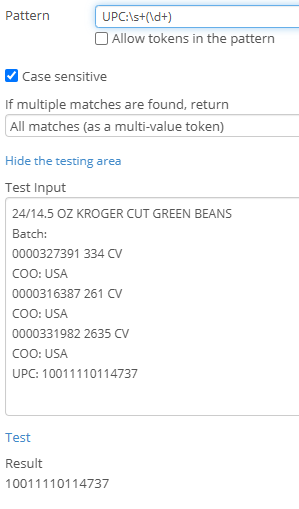
4) To get the UPC
UPC:\s+(\d+)
This captures all digits after the text "UPC:"