Hi Howard,
I'm not familiar enough with the SDK to give you a function-based answer, but I believe the SDK may be unnecessary in this case. Using Workflow, you are able to separate the pages of a document into single pages. The basic components of the workflow include a Find Entry or Search Repository activity to locate the document, then a Repeat loop to separate its pages. I show an example (with further explanation) below.
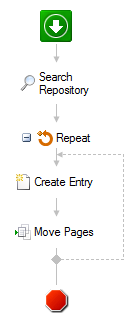
Within the Find Entry or Search Repository step, be sure to specify "Page Count" under Additional Properties - this pulls the number of pages in the document for use in the Repeat loop.
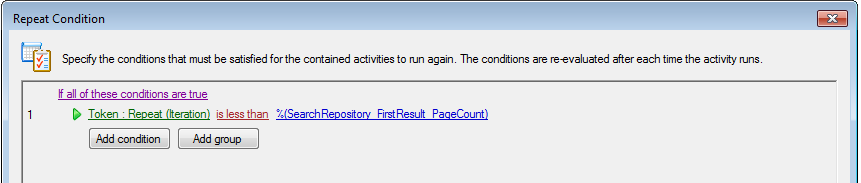
In the Repeat activity, the condition designates the number of times it will iterate. Configuring the condition as below tells the loop to run as many times as there are pages in the document.

Within the loop, each page of the document will go to the destination and will be named as specified in the Create Entry activity. I suggest using a token in the Entry Name to give each page a unique name. The %(Repeat_Iteration) token will name the new document according to the page number.
In the Move Pages activity, you will separate the document one page at a time. If you'd like to keep the original document, under Action select "Copy pages." Otherwise, select "Move pages" and "Delete document if all its pages have been moved." You will Move Pages From the document path found in the Search Repository (or Find Entry) step, and you will Move Pages To that designated in the Create Entry activity. If you are copying pages, the page number you pull out will be that of the current iteration; so, Page Range will be %(Repeat_Iteration). If moving pages, Page Range will be 1, i.e. the new first page.
Another Answers post that is useful can be found here. I hope this will be useful!