Using Pattern Matching, it should be easy to grab the information inside the brackets, regardless of which line it’s located on. Just build a Zone OCR region around the entire block of text, and use Pattern Matching to specify that it should only grab information within the brackets. You could probably get away with something as simple as:
\<(.+)\>
It seems like what you’re really looking for here is some basic conditional functionality. Essentially: IF there is information in brackets, THEN use that, ELSE use the name instead. This is something that is being built into Quick Fields 9.0 (which we’re looking forward to releasing in the near future), but for the time being is not available out-of-the-box in Quick Fields. That leaves us a few options, including using Workflow or building a custom script for Quick Fields, but I think there’s an easier solution: Pre-Classification Processing.
1. Build out three different document classes. One for documents with brackets one line 2, one for documents with brackets on line 3, and one for documents without brackets at all.
2. As part of pre-classification, capture each line of the address with a zone OCR.
3. Use Token Identification as part of each document class to identify which type of document it is. To see if the brackets are on line two, you’d use something like this:
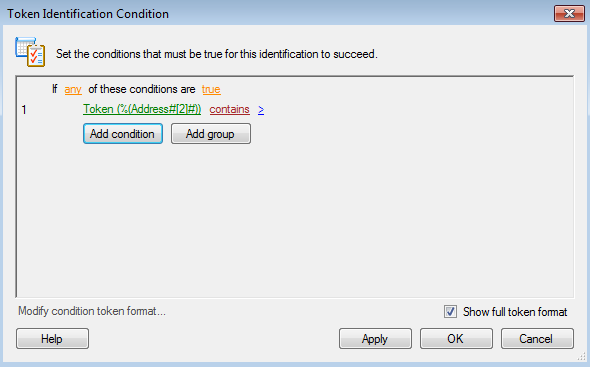
4. Do the same thing for documents with brackets on line 3, but using index value 3 rather than 2.
5. If the brackets are not one line 2 or 3, then they don’t exist, so you won’t need identification criteria for the third and final category.
6. Build out your session so that each type of document is handled appropriately. You’ll use pattern matching to strip out the brackets, and then just use the appropriate index value in the metadata to indicate names.