In short Yes.
However, in Laserfiche, there are a number of ways of accomplishing this.
If it's already in the repo then:
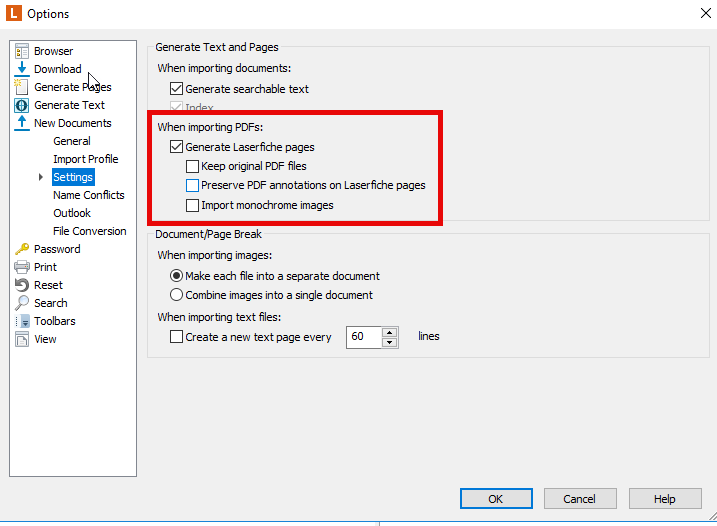
1. Generate pages: This step converts the PDF into image-based pages that Laserfiche can process. Right-click on the PDF document and select "Generate Pages."
2. OCR the generated pages: Once the pages are generated, you can then run OCR on these image-based pages. This process extracts the text from the images and makes it searchable.
This approach is appropriate because PDFs can contain various types of content, including text that's already searchable, images, and scanned content. By generating pages, Laserfiche ensures it has a consistent image-based format to work with for OCR.
It's worth noting that this process can increase storage requirements, as you'll now have both the original PDF and the generated pages. However, it allows for more comprehensive text extraction and searchability within the Laserfiche system.
If you're dealing with a large number of PDFs, you might want to consider automating this process. Laserfiche offers tools like Import Agent that can be configured to generate pages and perform OCR during the import process automatically.
For optimal results, ensure your PDFs are of good quality and properly oriented. If you're experiencing issues with certain PDFs, it might be related to factors like file size, font size, or document orientation.
Additionally, I would also suggest look at your document import settings to automate the page creation.