asked on September 21, 2021
Hi,
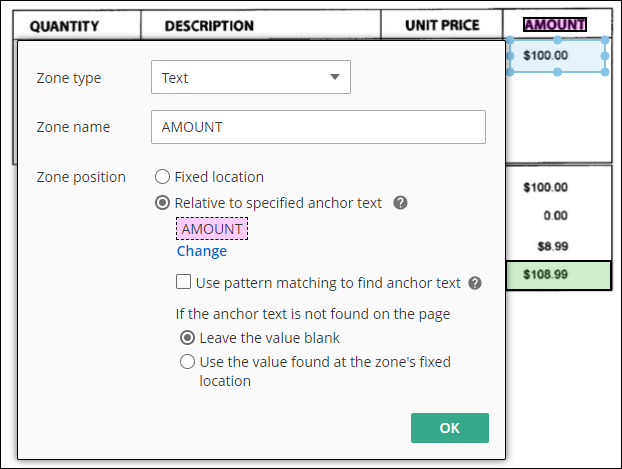
Can someone help with this pattern matching. I have this Average Essential Score i'm trying to pickup but not sure how to make this work. I went to this site https://regex101.com/ and I'm have a little trouble understanding it. So I figured it would be easier just asking the professional.
0
0