I think the challenge in situations like this is that what is "clear" to us is often difficult for software to interpret because it lacks the same contextual awareness.
Are you dealing with handwritten or printed text? If text is handwritten that's another story, but if it is printed then you may just need to refine the OCR settings to make it easier for the software to interpret.
From the Workflow side, as long as you have the correct number of characters, then you should be able to get around it even if the second / is misinterpreted.
For example,
Whether you have 06/01/2021, 06/0112021, or 0610112021 you still have 10 characters and all of the required data in the correct locations, so you could extract it several ways.
Example using Token Calculator
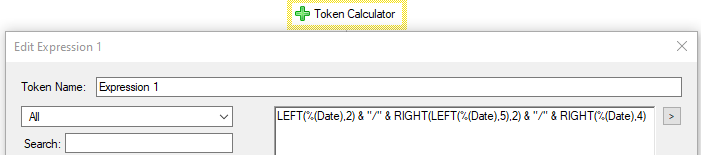
LEFT(%(Token),2) & "/" & RIGHT(LEFT(%(Token),5),2) & "/" & RIGHT(%(Token),4)
This approach just grabs each set of numbers based on location and puts them together.
Example using RegEx
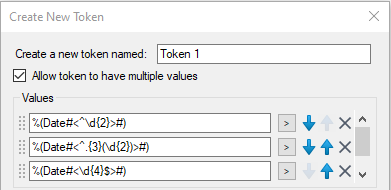
Here we're using RegEx to grab:
- The first 2 digit characters
- The first 2 digits after the first 3 characters
- The last 4 digits from the end
You could do this in a multi-value token like I did above and use indexing to put them together in the token editor
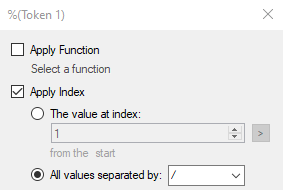
Or you could just build out the token and add your delimiters at the same time.
%(Token#<^\d{2}>#)/%(Token#<^.{3}(\d{2})>#)/%(Token#<\d{4}$>#)
I haven't used cloud capture so I don't know what options are available there, but if you have the ability to use RegEx you may be able to pull this off within the capture process instead of workflow.
Basically, instead of fighting to make it "read" the / correctly, just focus on the position of the characters you need; even if it misreads a slash as a 1, everything else is still in the right place.