If I'm understanding what you are trying to do, here is one way (definitely not the only way) to complete that.
This loads some details of the entries into a multi-value token in LFWorkflow (the date, since that is what we are sorting by, the file name because I'm using that as the secondary sort option, and the entry ID as both the third sorting option and the way to identify the entry when it is time to push the sorted values back to the metadata fields. Those are loaded into a string of text, as date (yyyy-MM-dd format), the file name, and the entry ID - in this layout, we can just sort the strings alphabetically.
After the multi-value token is sorted, we go through each value, using the entry ID to retrieve the entry and then populate the iteration value to the other field.
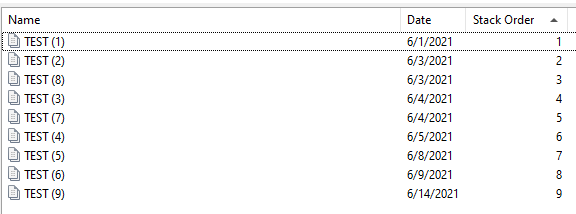
Here's what it looks like before (my fields are named Date and Stack Order - you can name them what you want, I just wanted to use fields I already had set-up).

After running the Workflow, here's how the results look. You can see that all of the Stack Order fields have been populated, and if sorting by the column, you can see that the values are sorted in date order (with name as secondary sort):
Here's the set-up in LFWorkflow:
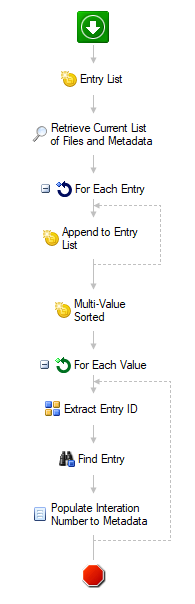
- Entry List - creates a single multi-value string token named "Entry Details".
- Retrieve Current List of Files and Metadata - searches your folder in the repository. Make sure you select the "Date" field in the list of fields that are returned with the search results.
- For Each Entry - this cycles through the results from "Retrieve Current List of Files and Metadata".
- Append to Entry List - this appends 3 values to the "Entry Details" token: %(ForEachEntry_CurrentEntry_Date#"yyyy-MM-dd"#) - Name: %(ForEachEntry_CurrentEntry_Name) - ID#%(ForEachEntry_CurrentEntry_ID)
- %(ForEachEntry_CurrentEntry_Date#"yyyy-MM-dd"#) is the date from the search results, formatted as yyyy-MM-dd so that it can sort alphabetically.
- Name: %(ForEachEntry_CurrentEntry_Name) is the word "Name:" followed by the actual file name. In this case of two files having the same date, this will allow the file name to be the secondary sort option.
- ID#%(ForEachEntry_CurrentEntry_ID) is the word "ID#" followed by the entry ID number. This will allow it to act as a third sort option, but more importantly will allow us to retrieve the entry ID later in order to populate the values back to the metadata.
- Multi-Value Sorted - this creates a new token named "Multi-Value Sorted" which takes the "Entry Details" token as runs a Sort Ascending function on it. Token value should look like this: %(Entry Details#@SortAscending@#)
- For Each Value - this cycles through all values in the "Multi-Value Sorted" token.
- Extract Entry ID - this a pattern matching activity to retrieve the entry ID from the string values of "Multi-Value Sorted".
- Input is: %(ForEachValue_Current Value)
- Pattern is: ID#(\d{1,15})
- This looks for the word "ID#" immediately followed by 1-15 numbers, and retrieves those numbers.
- Return the first match only.
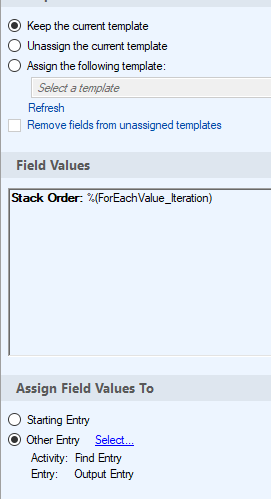
- Find Entry - this should be finding the entry with ID equal to the value retrieved from the "Extract Entry ID" activity. It should look like this: %(ExtractEntryID_Entry ID)
- Populate Interation Number to Metadata - be sure to select the entry that is found in the "Find Entry" activity, and populate the Stack Order field with the "For Each Value - Iteration" token. Should look like this: