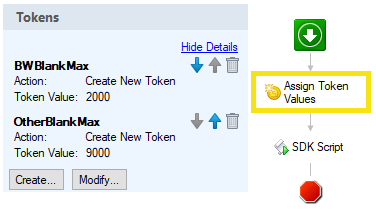
As Ben stated and somewhat showed, you can check the PageInfo for file size and remove pages that are smaller than a predefined amount. You must be careful when doing this that you do not set the value too high and then have it delete pages that have a small amount of data on them. Here is a simple workflow that if the image size for Black and White image is less than the value of BWBlankMax or not Black and White image is less than OtherBlankMax value, will delete the page. This will get some blanks but if the page is a dirty scan (a lot of speckling), has holes punched, ragged edge, or boarder the size will be above the threshold and the page will not be deleted.
Here is the code for a VB SDK Script
Protected Overrides Sub Execute()
'Write your code here. The BoundEntryInfo property will access the entry, RASession will get the Repository Access session
If BoundEntryInfo.EntryType = EntryType.Document Then
Dim sBWBlankMax As String = GetTokenValue("BWBlankMax")
Dim sOtherBlankMax As String = GetTokenValue("OtherBlankMax")
Dim iBWBlankMax As Integer
Dim iOtherBlankMax As Integer
' Get Black and White Blank Page size value
If Integer.TryParse(sBWBlankMax, iBWBlankMax) Then
' Get non Black and White Blank Page size value
If Integer.TryParse(sOtherBlankMax, iOtherBlankMax) Then
Try
' Cast the Bound Entry to DocumentInfo
Using oLFDocInfo As DocumentInfo = DirectCast(BoundEntryInfo, DocumentInfo)
' Get PageInfoReader with pages from DocumentInfo
Using oLFPageInfoReader As PageInfoReader = oLFDocInfo.GetPageInfos()
' Iterate through each PageInfo
For Each oLFPageInfo As Laserfiche.RepositoryAccess.PageInfo In oLFPageInfoReader
'Check for Black and White and image size
If oLFPageInfo.ImageDepth = 1 And oLFPageInfo.ImageDataSize < iBWBlankMax Then
' Delete pages that are saller image size then set point
oLFPageInfo.Delete()
'Check for Non Black and White and image size
ElseIf oLFPageInfo.ImageDepth > 1 And oLFPageInfo.ImageDataSize < iOtherBlankMax Then
' Delete pages that are saller image size then set point
oLFPageInfo.Delete()
End If
' Save any changes to the PageInfo object
oLFPageInfo.Save()
Next
End Using
End Using
Catch ex As Exception
' Report error message
WorkflowApi.TrackWarning(ex.Message)
End Try
End If
End If
End If
End Sub
