Hi Ricardo,
We had a similar process to what you are outlining to cleanup some of our documents. It was not as straight forward as I thought it might. I will try and explain what we did.
Our workflow:
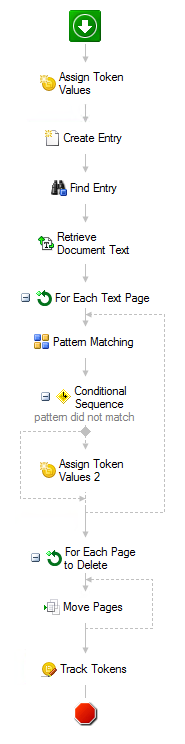
Assign Token Values - creates a multi-value token of the will hold page numbers to be deleted
Create Entry - creates an entry (document) to move the deleted pages to. This entry can later be deleted but we need somewhere to move the pages we want to delete to.
Find Entry - the entry that is to have pages removed.
Retrieve Document Text - Retrieve the OCR text of the document. Key here is to select the token option, "For each page, create a separate value in the multi-value Text token. This allows us to iterate over each individual page and perform our pattern match.

For Each Text Page - This is a 'repeat for each value' activity, with the value being the retrieve document text %(RetrieveDocumentText_Text)
We are now looking at each individual page of the document and can perform our -
Pattern Matching - match on a pattern for a page that should be kept
Conditional Sequence - If the pattern matching did not match. (The pattern match token is empty.) We then:
Assign Token Values 2 - Append the page number that will be deleted to the token created in step 1. The page number is the iteration of the 'For Each Text Page' loop. %(ForEachTextPage_Iteration)
Once our loop is complete the token created in step 1 has a list of the page numbers to be deleted. However, we want to delete pages starting with the largest page number so that page numbers remain accurate.
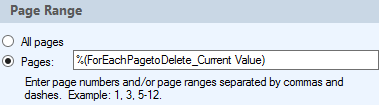
For Each Page to Delete - another 'repeat for each value' loop. The value that we loop on is the token from step 1 but adding (via the token dialog) the 'Sort Descending' function.
%(pages_to_delete#@SortDescending@#)
Move Pages - we now move pages from our original document to the entry we created in step 2. The page that is to be moved is the current value of our loop, %(ForEachPagetoDelete_Current Value). The activity will not prompt you to select the token, you have to enter it manually.
Once complete the original document should have the pages removed. The document that we created in step 2 will have the delete pages and can be removed.
Clear as mud?
Key to being able to pattern match is to use the 'create separate value' token option in the retrieve document text activity so that each page can be looked at individually and then to move pages starting with the largest page number first to keep the document in order. Of course the 'find entry' could be replaced with a search/loop function and the pattern matching logic reversed.
Hopefully this helps a bit.