SELECTED ANSWER
replied on April 10, 2017
If you're doing this in Workflow, then you'll need a SDK script activity. In it, you need to add references to Laserfiche.DocumentServices (the version should match the version of Laserfiche.RepositoryAccess, which matches the version of your Workflow installation) and System.IO. In the Script's Default Entry section in the activity's properties, set the entry you want exported. If using Find Entry, then pick the entry you found:
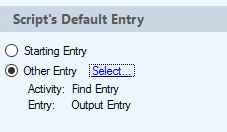
The script looks like this:
DocumentInfo doc = (DocumentInfo)this.BoundEntryInfo;
DocumentExporter docExporter = new DocumentExporter();
string exportPath = @"c:\temp\test.tif";
int pageNumber = 1;
docExporter.PageFormat = DocumentPageFormat.Tiff;
using (FileStream fs = File.OpenWrite(exportPath))
docExporter.ExportPage(doc, pageNumber, fs);
The Workflow server service user needs write access to the folder where you'll be saving these files.
If you're not running this code in Workflow, then you need to make your own connection to Laserfiche and "%(SearchRepository_FirstResult_ID)" is just a string.